Introduction to SDMs: simple model fitting
RStudio project
Open the RStudio project that we created in the first session. I recommend to use this RStudio project for the entire course and within the RStudio project create separate R scripts for each session.
- Create a new empty R script by going to the tab “File”, select “New File” and then “R script”
- In the new R script, type
# Session 5: SDM introductionand save the file in your folder “scripts” within your project folder, e.g. as “5_SDM_intro.R”
1 Introduction
This session will introduce you to simple species distribution models (SDMs). Species distribution models (SDMs) are a popular tool in quantitative ecology (Franklin 2010; Peterson et al. 2011; Guisan, Thuiller, and Zimmermann 2017) and constitute the most widely used modelling framework in global change impact assessments for projecting potential future range shifts of species (IPBES 2016). There are several reasons that make them so popular: they are comparably easy to use because many software packages (e.g. Thuiller et al. 2009; Phillips, Anderson, and Schapire 2006) and guidelines (e.g. Elith, Leathwick, and Hastie 2008; Elith et al. 2011; Merow, Smith, and Silander Jr 2013; Guisan, Thuiller, and Zimmermann 2017) are available, and they have comparably low data requirements.
SDMs relate biodiversity observations (e.g. presence-only, presence/absence, abundance, species richness) at specific sites to the prevailing environmental conditions at those sites. Different statistical and machine-learning algorithms are available for this. Based on the estimated biodiversity-environment relationship, we can make predictions in space and in time by projecting the model onto available environmental layers (Figure 1).
 is used to estimate the species-environment relationship. Third, the species–environment relationship can be mapped onto geographic layers of environmental information to delineate the potential distribution of the species. Mapping to the sampling area and period is usually referred to as interpolation, while transferring to a different time period or geographic area is referred to as extrapolation.**")
We distinguish five main modelling steps for SDMs: (i) conceptualisation, (ii) data preparation, (iii) model fitting, (iv) model assessment, and (v) prediction (Figure 2.). The last step (prediction) is not always part of SDM studies but depends on the model objective (Zurell et al. 2020). Generally, we distinguish three main objectives for SDMs: (a) inference and explanation, (b) mapping and interpolation, and (c) forecast and transfer. I recommend getting more familiar with critical assumptions and modelling decisions by studying the many excellent review articles (Guisan and Zimmermann 2000; Guisan and Thuiller 2005; Elith and Leathwick 2009) and textbooks on SDMs (Peterson et al. 2011; Franklin 2010; Guisan, Thuiller, and Zimmermann 2017).
I would also like to emphasise that model building is an iterative process and there is much to learn on the way. In consequence, you may want to revisit and improve certain modelling steps, for example improve the spatial sampling design. Because of that I like to regard model building as a cycle rather than a workflow with a pre-defined termination point (Figure 2.)(Zurell et al. 2020).

1.1 Prac overview
In this session, we will only work with Generalised Linear Models (GLMs) and concentrate on the first three model building steps (Figure 2.)
1.2 Generalised linear models (GLMs)
Why do we not simply use linear regression to fit our species-environment relationship? Well, strictly, ordinary least squares (OLS) linear regression is only valid if the response (or rather the error) is normally distributed and ranges (\(-\infty,\infty\)). OLS regression looks like this
\[E(Y|X)=\beta X+\epsilon\]
where \(E(Y|X)\) is the conditional mean, meaning the expected value of the response \(Y\) given the environmental predictors \(X\) (Hosmer and Lemeshow 2013). \(X\) is the matrix of predictors (including the intercept), \(\beta\) are the coefficients for the predictors, and \(\epsilon\) is the (normally distributed!) error term. \(\beta X\) is referred to as the linear predictor.
When we want to predict species occurrence based on environment, then the conditional mean \(E(Y|X)\) is binary and bounded between 0 (absence) and 1 (presence). Thus, the assumptions of OLS regression are not met. GLMs are more flexible regression models that allow the response variable to follow other distributions. Similar to OLS regression, we also fit a linear predictor \(\beta X\) and then relate this linear predictor to the mean of the response variable using a link function. The link function is used to transform the response to normality. In case of a binary response, we typically use the logit link (or sometimes the probit link). The conditional mean is then given by:
\[E(Y|X) = \pi (X) = \frac{e^{\beta X+\epsilon}}{1+e^{\beta X+\epsilon}}\]
The logit transformation is defined as: \[g(X) = ln \left( \frac{\pi (X)}{1-\pi (X)} \right) = \beta X+\epsilon\]
The trick is that the logit, g(X), is now linear in its parameters, is continuous and may range (\(-\infty,\infty\)). GLMs with a logit link are also called logistic regression models.
2 Conceptualisation
In the conceptualisation phase, we formulate our main research objectives and decide on the model and study setup based on any previous knowledge on the species and study system. An important point here is whether we can use available data or have to gather own biodiversity (and environmental) data, which would require deciding on an appropriate sampling design. Then, we carefully check the main underlying assumptions of SDMs, for example whether the species is in pseudo-equilibrium with environment and whether the data could be biased in any way (cf. chapter 5 in Guisan, Thuiller, and Zimmermann 2017). The choice of adequate environmental predictors, of modelling algorithms and of desired model complexity should be guided by the research objective and by hypotheses regarding the species-environment relationship. We can divide environmental variables into three types of predictors: resource variables, direct variables and indirect variables (Austin 1980; Guisan and Zimmermann 2000).
2.1 Example: Eurasian lynx
We aim at assessing potential climate change effects on the Eurasian lynx (Lynx lynx) in Europe (Figure 3), a middle-sized carnivore of Central, Northern and Easter Europe and Asia. First, we try to make ourselves familiar with Lynx ecology, for example through the IUCN website). Think about which factors could limit the distribution of lynx in Europe.

3 Data preparation
In this step, the actual biodiversity and environmental data are gathered and processed. This concerns all data that are required for model fitting but also data that are used for making transfers. Here, we will use the rasterised mammal data set from practical 3 at 1° spatial resolution. This is a very coarse resolution and we need to be aware that we model coarse-scale environmental (or climate) relationships rather than fine-scale habitat choice.
Read in the data:
library(raster)
library(letsR)
load('data/r_mammals_eur.RData')
lynx_dist <- data.frame(r_mammals_eur$Presence_and_Absence_Matrix[,1:2],
occ = r_mammals_eur$Presence_and_Absence_Matrix[,'Lynx lynx'])
# plot the distribution
plot(rasterFromXYZ(lynx_dist))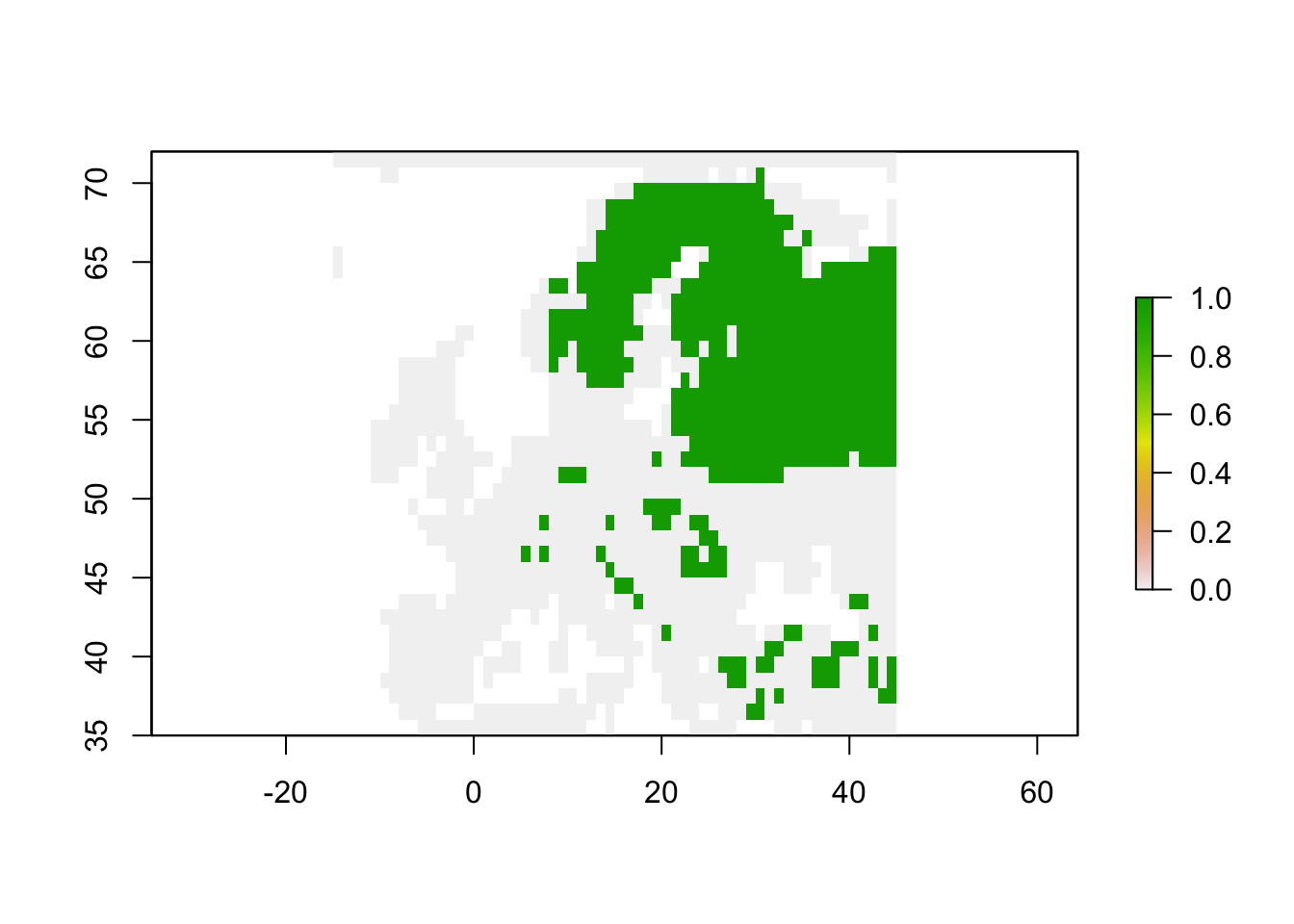
We also retrieve climate data from worldclim (https://www.worldclim.org/). The coarsest resolution offered for download is 10 min, which we aggregate to 1° resolution to match the lynx data.
# Set download=T if you haven't downloaded the data in the previous practical
clim <- getData("worldclim", var="bio", res=10, download=F, path="data")# Aggregate to 1° resolution
clim_1deg <- aggregate(clim, 6)
# Merge with Lynx data
lynx_dist <- data.frame(lynx_dist,
raster::extract(x = clim_1deg, y = lynx_dist[,1:2]))
# Exclude NAs (cells without climate data)
lynx_dist <- na.exclude(lynx_dist)The data provide us with presence and absence information. However,
to avoid problems with spatial autocorrelation in our SDMs, we should
spatially thin these data such that they do not contain adjacent cells.
There are different ways to do the thinning. A particularly fast one is
the gridSample() function in the dismo
package.
library(dismo)
# We create a background map at 1° spatial resolution with European land masses - this is only for plotting purposes
bg <- rasterFromXYZ(lynx_dist[,1:3])
values(bg)[!is.na(values(bg))] <- 0
# We only want to have one record per 2°x2° and use a mask to achieve this
mask <- aggregate(bg,2)
# Thinned coordinates
set.seed(54321)
xy <- gridSample(lynx_dist[,1:2], mask, n=1)
# Checking number of data points
nrow(xy)## [1] 423nrow(lynx_dist)## [1] 1438# Reducing the Lynx data
lynx_thinned <- merge(xy,lynx_dist)
# Plot European land mass
plot(bg,col='grey',axes=F,legend=F)
# Plot presences in red and absences in black
points(lynx_thinned[,1:2],pch=19,col=c('black','red')[as.factor(lynx_thinned$occ)])
4 Model fitting
4.1 Fitting our first GLM
Before we start into the complexities of the different model fitting
steps, let us look at a GLM in more detail. We fit our first GLM with
only one predictor assuming a linear relationship between response and
predictor. The glm function is contained in the R
stats package. We need to specify a formula describing
how the response should be related to the predictors, and the
data specifying the data frame that contains the response and
predictor variables, and a family argument specifying the type
of response and the link function. In our case, we use the
logit link in the binomial family.
# We first fit a GLM for the bio11 variable assuming a linear relationship:
m1 <- glm(occ ~ bio11, family="binomial", data= lynx_thinned)
# We can get a summary of the model:
summary(m1) ##
## Call:
## glm(formula = occ ~ bio11, family = "binomial", data = lynx_thinned)
##
## Deviance Residuals:
## Min 1Q Median 3Q Max
## -2.1111 -0.5182 -0.1931 0.5379 2.5215
##
## Coefficients:
## Estimate Std. Error z value Pr(>|z|)
## (Intercept) -1.927642 0.213014 -9.049 <2e-16 ***
## bio11 -0.033683 0.003295 -10.222 <2e-16 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## (Dispersion parameter for binomial family taken to be 1)
##
## Null deviance: 531.29 on 422 degrees of freedom
## Residual deviance: 309.04 on 421 degrees of freedom
## AIC: 313.04
##
## Number of Fisher Scoring iterations: 64.1.1 Deviance and AIC
Additional to the slope values, there are a few interesting metrics printed in the output called deviance and AIC. These metrics tell us something about how closely the model fits the observed data.
Basically, we want to know whether a predictor is “important”. We thus need to evaluate whether a model including this variable tells us more about the response than a model without that variable (Hosmer and Lemeshow 2013). Importantly, we do not look at the significance level of predictors. Such p-values merely tell us whether the slope coefficient is significantly different from zero. Rather, we assess whether the predicted values are closer to the observed values when the variable is included in the model versus when it is not included.
In logistic regression, we compare the observed to predicted values using the log-likelihood function:
\[L( \beta ) = ln[l( \beta)] = \sum_{i=1}^{n} \left( y_i \times ln[\pi (x_i)] + (1-y_i) \times ln[1- \pi (x_i)] \right)\]
\(L( \beta )\) is the Likelihood of the fitted model. From this, we can calculate the deviance \(D\) defined as:
\[D = -2 \times L\]
In our model output, the deviance measure is called
Residual deviance. This deviance is an important measure
used for comparing models. For example, it serves for the calculation of
Information criteria that are used for comparing models
containing different numbers of parameters. One prominent measure is the
Akaike Information Criterion, usually abbreviated as AIC. It is
defined as: \[AIC = -2 \times L + 2 \times
(p+1) = D + 2 \times (p+1)\]
where \(p\) is the number of regression coefficients in the model. AIC thus takes into account model complexity. In general, lower values of AIC are preferable.
We can also use the deviance to calculate the Explained
deviance \(D^2\), which is the
amount of variation explained by the model compared to the null
expectation: \[D^2 = 1 -
\frac{D(model)}{D(Null.model)}\] The model output also provides
the Null deviance, so we can easily calculate the explained
deviance \(D^2\).
4.2 More complex GLMs
We can also fit quadratic or higher polynomial terms (check
?poly) and interactions between predictors:
- the term I()indicates that a variable should be
transformed before being used as predictor in the formula
- poly(x,n) creates a polynomial of degree \(n\): \(x + x^2 +
... + x^n\)
- x1:x2 creates a two-way interaction term between
variables x1 and x2, the linear terms of x1 and x2 would have to be
specified separately
- x1*x2 creates a two-way interaction term between
variables x1 and x2 plus their linear terms
- x1*x2*x3 creates the linear terms of the three variables,
all possible two-way interactions between these variables and the
three-way interaction
Try out different formulas:
# Fit a quadratic relationship with bio11:
m1_q <- glm(occ ~ bio11 + I(bio11^2), family="binomial", data= lynx_thinned)
summary(m1_q)
# Or use the poly() function:
summary( glm(occ ~ poly(bio11,2) , family="binomial", data= lynx_thinned) )
# Fit two linear variables:
summary( glm(occ ~ bio11 + bio8, family="binomial", data= lynx_thinned) )
# Fit three linear variables:
summary( glm(occ ~ bio11 + bio8 + bio17, family="binomial", data= lynx_thinned) )
# Fit three linear variables with up to three-way interactions
summary( glm(occ ~ bio11 * bio8 * bio17, family="binomial", data= lynx_thinned) )
# Fit three linear variables with up to two-way interactions
summary( glm(occ ~ bio11 + bio8 + bio17 +
bio11:bio8 + bio11:bio17 + bio8:bio17,
family="binomial", data= lynx_thinned) )Exercise:
Compare the different models above.
- Which model is the best in terms of AIC?
- What is the explained deviance of the different models?
- HINTS: you can extract the metrics using
AIC(m1),deviance(m1)andm1$null.deviance
4.3 Important considerations during model fitting
Model fitting is at the heart of any SDM application. Important aspects to consider during the model fitting step are:
- How to deal with multicollinearity in the environmental data?
- How many variables should be included in the model (without overfitting) and how should we select these?
- Which model settings should be used?
- When multiple model algorithms or candidate models are fitted, how to select the final model or average the models?
- Do we need to test or correct for non-independence in the data (spatial or temporal autocorrelation, nested data)?
- Do we want to threshold the predictions, and which threshold should be used?
More detailed descriptions on these aspects can be found in Franklin (2010) and in Guisan, Thuiller, and Zimmermann (2017).
4.4 Collinearity and variable selection
GLMs (and many other statistical models) have problems to fit stable parameters if two or more predictor variables are highly correlated, resulting in so-called multicollinearity issues (Dormann et al. 2013). To avoid these problems here, we start by checking for multi-collinearity and by selecting an initical set of predictor variables. Then, we can fit our GLM including multiple predictors and with differently complex response shapes. This model can then be further simplified by removing “unimportant” predictors.
4.4.1 Correlation among predictors
We first check for pairwise correlations among predictors. Generally, correlations below |r|<0.7 are considered unproblematic (or below |r|<0.5 as more conservative threshold).
library(corrplot)
# We first estimate a correlation matrix from the predictors.
# We use Spearman rank correlation coefficient, as we do not know
# whether all variables are normally distributed.
cor_mat <- cor(lynx_thinned[,-c(1:3)], method='spearman')
# We can visualise this correlation matrix. For better visibility,
# we plot the correlation coefficients as percentages.
corrplot.mixed(cor_mat, tl.pos='lt', tl.cex=0.6, number.cex=0.5, addCoefasPercent=T)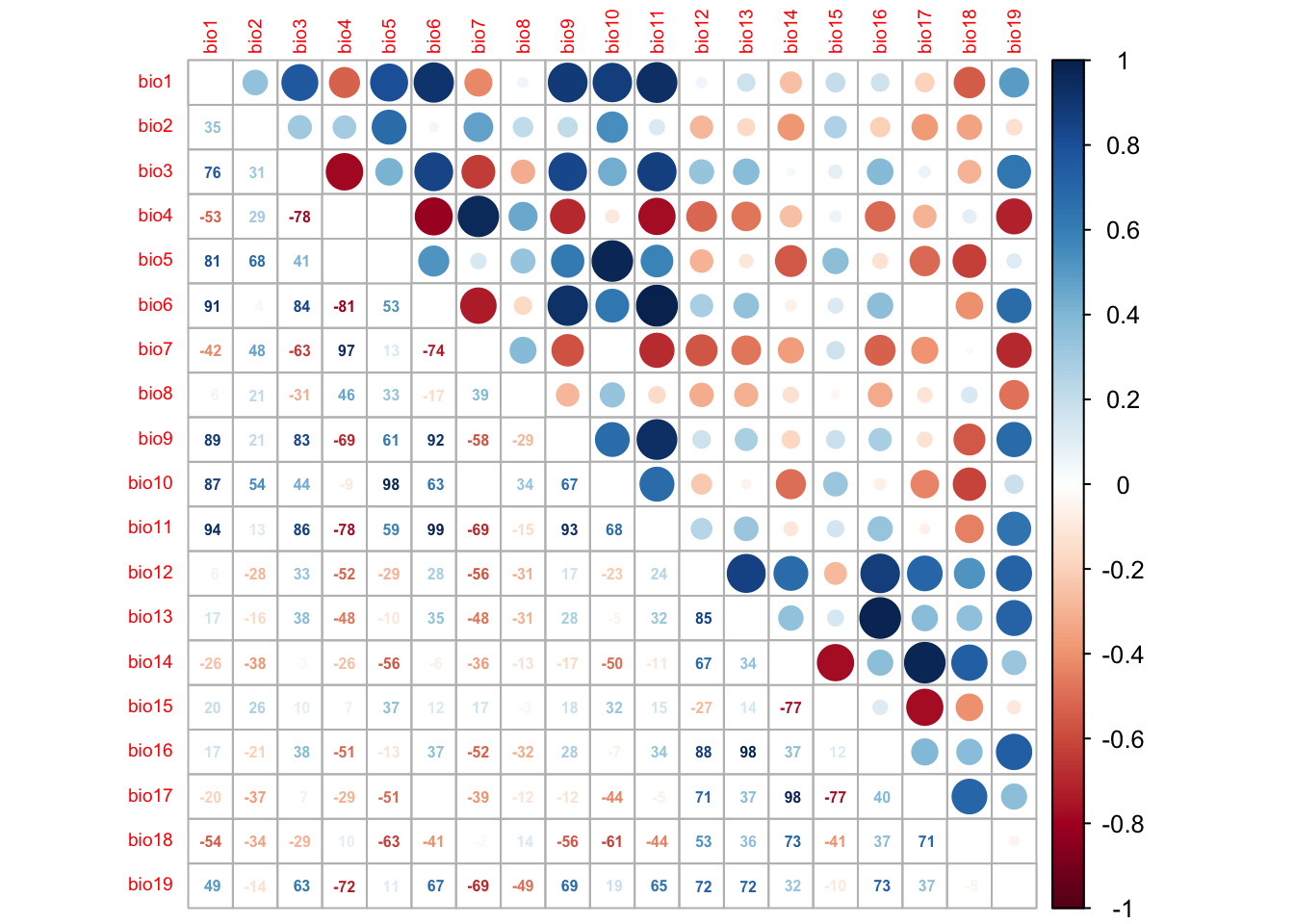
Several predictor variables are highly correlated. One way to deal with this issue is to remove the “less important” variable from the highly correlated pairs. For this, we need to assess variable importance.
4.5 Model selection
Now that we have selected a set of weakly correlated variables, we can fit the full model and then simplify it. The latter is typically called model selection. Here, I only use the two most important variables and include linear and quadratic terms in the full model.
# Fit the full model:
m1 <- glm( occ ~ bio11 + I(bio11^2) + bio10 + I(bio10^2),
family='binomial', data=lynx_thinned)
# Inspect the model:
summary(m1)##
## Call:
## glm(formula = occ ~ bio11 + I(bio11^2) + bio10 + I(bio10^2),
## family = "binomial", data = lynx_thinned)
##
## Deviance Residuals:
## Min 1Q Median 3Q Max
## -2.1214 -0.4037 -0.0303 0.4276 3.2879
##
## Coefficients:
## Estimate Std. Error z value Pr(>|z|)
## (Intercept) -1.808e+01 3.084e+00 -5.862 4.56e-09 ***
## bio11 -4.721e-02 8.967e-03 -5.265 1.40e-07 ***
## I(bio11^2) -1.101e-04 7.988e-05 -1.379 0.168
## bio10 2.256e-01 4.178e-02 5.400 6.68e-08 ***
## I(bio10^2) -7.561e-04 1.418e-04 -5.334 9.60e-08 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## (Dispersion parameter for binomial family taken to be 1)
##
## Null deviance: 531.29 on 422 degrees of freedom
## Residual deviance: 259.86 on 418 degrees of freedom
## AIC: 269.86
##
## Number of Fisher Scoring iterations: 8How much deviance is explained by our model? The function
expl_deviance() is also contained in the
mecofun package. As explained earlier, we can calculate
explained deviance by quantifying how closely the model predictions fit
the data in relation to the null model predictions.
# Explained deviance:
expl_deviance(obs = lynx_thinned$occ,
pred = m1$fitted)## [1] 0.5108966We can simplify the model further by using stepwise variable
selection. The function step() uses the AIC to compare
different subsets of the model. Specifically, it will iteratively drop
variables and add variables until the AIC cannot be improved further
(meaning it will not decrease further).
m_step <- step(m1) # Inspect the model:
summary(m_step)##
## Call:
## glm(formula = occ ~ bio11 + bio10 + I(bio10^2), family = "binomial",
## data = lynx_thinned)
##
## Deviance Residuals:
## Min 1Q Median 3Q Max
## -2.22910 -0.40878 -0.05073 0.37329 3.08947
##
## Coefficients:
## Estimate Std. Error z value Pr(>|z|)
## (Intercept) -1.900e+01 3.124e+00 -6.084 1.17e-09 ***
## bio11 -3.719e-02 4.188e-03 -8.880 < 2e-16 ***
## bio10 2.355e-01 4.228e-02 5.571 2.53e-08 ***
## I(bio10^2) -7.793e-04 1.433e-04 -5.437 5.41e-08 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## (Dispersion parameter for binomial family taken to be 1)
##
## Null deviance: 531.29 on 422 degrees of freedom
## Residual deviance: 261.81 on 419 degrees of freedom
## AIC: 269.81
##
## Number of Fisher Scoring iterations: 7# Explained deviance:
expl_deviance(obs = lynx_thinned$occ,
pred = m_step$fitted)## [1] 0.50721The final model only selected the linear terms for bio11 and bio8. The explained deviance is a tiny bit lower than for the quadratic model, but the linear model is more parsimonious.
Finally, don’t forget to save the data.
save(bg, clim_1deg, lynx_thinned, pred_sel, file='data/lynx_thinned.RData')Exercise:
Fit the full model containing all weakly correlated variables.
- Look up the eight weakly correlated variables in the object
pred_sel. - Define a full model with these eight variables including their linear and quadratic terms.
- Run the full model.
- Simplify the model using stepwise variable selection
step() - Compare the full model and the reduced model in terms of AIC and explained deviance.